Every time you type a question into Google, something remarkable happens in a fraction of a second. A system processes your words, understands your intent, searches through hundreds of billions of web pages, evaluates each one against hundreds of signals, and returns a ranked list of results tailored specifically to you.
It does this roughly 8.5 billion times a day.
Understanding how that process works is not just academically interesting. It is the foundation of every effective SEO decision you will ever make. When you understand what search engines are actually doing, you stop guessing and start building strategy based on how the system genuinely works.
This guide covers everything, from how search engines discover content in the first place to how Google’s AI systems understand your words, rank pages, and generate the AI-powered answers that are reshaping search in 2026.
What is a Search Engine?
A search engine is a software system designed to search for information on the internet, organise it, and return the most relevant results in response to a user’s query.
The most widely used search engine in the world is Google, which holds approximately 90% of the global search market. Others include Bing (Microsoft), Yahoo, Baidu (dominant in China), and Yandex (dominant in Russia). DuckDuckGo serves users who prioritise privacy.
In 2026, the definition of “search engine” has expanded. AI-powered tools like ChatGPT Search, Perplexity, and Google AI Mode now function as search interfaces, retrieving and synthesising information from across the web rather than simply listing links. But the underlying principles of how web content is discovered, evaluated, and surfaced remain consistent across all of these systems.
What Search Engines Are Trying to Do
To understand how search engines work, you first need to understand their goal.
Google’s stated mission is to “organise the world’s information and make it universally accessible and useful.” In practice, that means one thing above all else: returning the most helpful, accurate, and relevant result for any given search query.
Every decision a search engine makes, from which pages to crawl to how it ranks results, flows from that single objective. If you understand that search engines are trying to serve users, not websites, everything about SEO makes more sense.
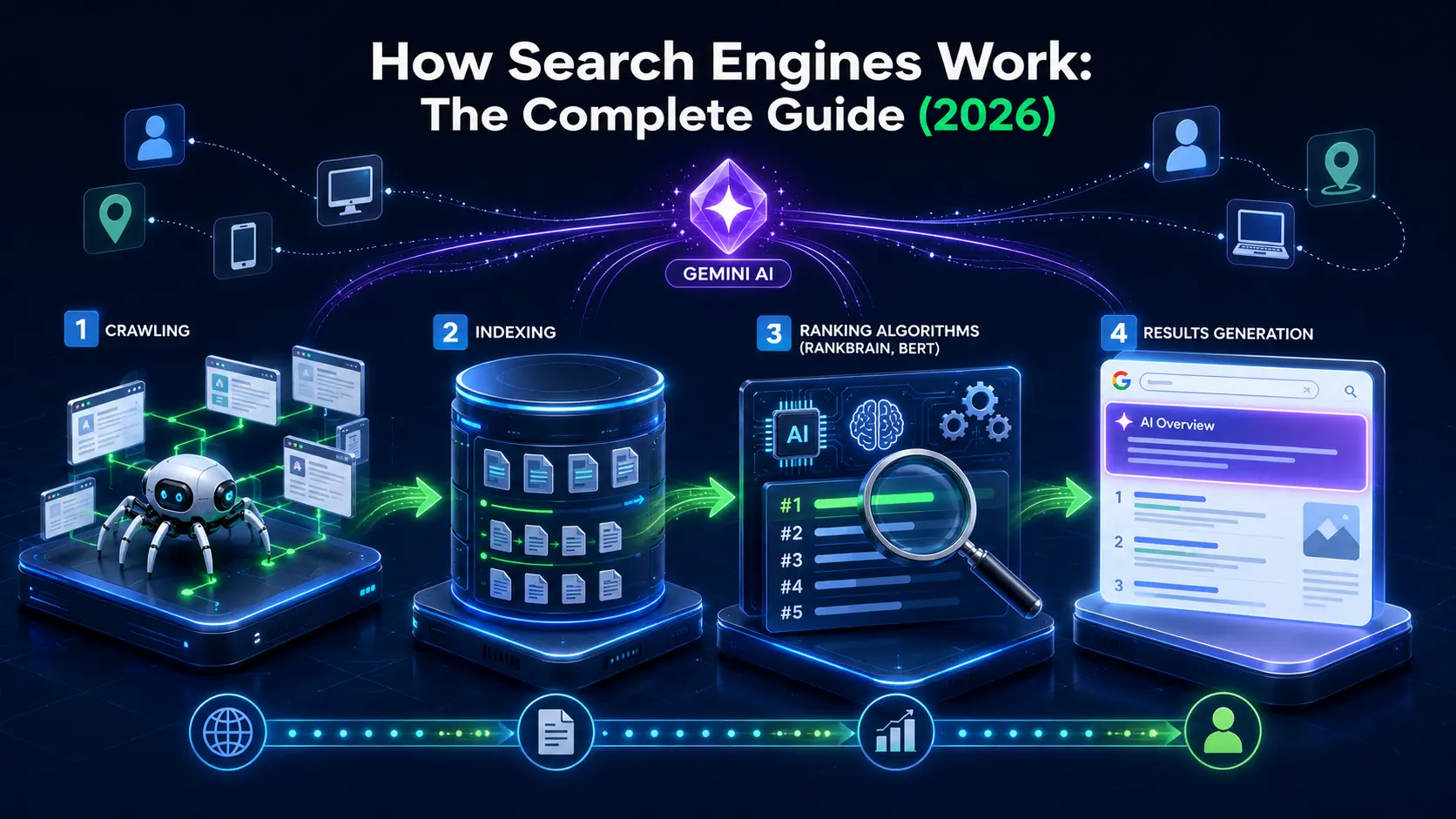
The Four Stages of How a Search Engine Works
Modern search engines operate through four sequential stages: crawling, indexing, ranking, and results generation. In 2026, a fifth stage, AI synthesis, now sits on top of the traditional pipeline for many queries.
Stage 1: Crawling
Crawling is the process by which search engines discover content on the internet. It is carried out by automated software programmes called crawlers, spiders, or bots. Google’s crawler is called Googlebot.
How Crawlers Discover Pages
Crawlers navigate the web by following links. They start from a set of known URLs, visit those pages, read their content, collect all the links on those pages, and then follow those links to discover new pages. This process repeats continuously across the entire web.
Think of it like a librarian who starts with one book, reads it, notices references to other books, goes and reads those, and keeps following references indefinitely.
New pages that have no links pointing to them are extremely difficult for crawlers to find. This is why internal linking and backlinks matter so much in SEO. If no page links to a piece of content, it is effectively invisible to search engines.
Discovery Crawl vs Refresh Crawl
In 2026, Google splits its crawling into two distinct types:
Discovery crawl — a resource-intensive process reserved for finding completely new URLs that Google has never seen before.
Refresh crawl — a lighter, more frequent process that revisits already-known pages to check whether the content has been updated.
Understanding this distinction matters practically. A new piece of content goes through the discovery process, which takes longer. Existing content that you update gets refreshed more quickly, especially if your site has a strong crawl history with Google.
Crawl Budget
Search engines have finite computing resources. Google cannot crawl every page on every website every day. Each website is allocated a crawl budget, which is the number of pages Google will crawl on your site within a given time period.
For small websites with dozens or a few hundred pages, crawl budget is rarely a concern. But for large websites with thousands of pages, crawl budget management becomes critical. Wasted crawl budget on low-value pages (duplicates, thin content, internal search result pages) means important pages may be crawled less frequently.
What Happens When Googlebot Visits a Page
When Googlebot visits a URL, it:
- Downloads the HTML of the page
- Renders the page, meaning it processes JavaScript to see the fully loaded version (this is known as “rendering” and is a separate, more resource-intensive step)
- Extracts all the text, links, and structured data on the page
- Passes the information to the indexing system
Pages that rely heavily on JavaScript for their content require extra resources to render. Googlebot does not always render pages immediately, which can delay indexing of JavaScript-heavy content.
What Can Block Crawling
Several things can prevent Googlebot from accessing your content:
- Robots.txt — a file on your website that instructs crawlers which pages or directories not to access. Incorrectly configured robots.txt files can accidentally block crawlers from important content.
- Login walls — content that requires a user to be logged in cannot be crawled.
- Noindex tags — HTML tags that tell crawlers a page should not be indexed. These do not necessarily block crawling, but they prevent indexing.
- Server errors — if your server returns error codes (like 500 errors) when Googlebot visits, it cannot access your content.
- Crawl rate limits — if your server is slow or unstable, Googlebot will crawl it less frequently to avoid overloading it.
Stage 2: Indexing
Once Googlebot has crawled a page, the content is processed and stored in Google’s index. The index is a massive database containing information about every web page Google has discovered and analysed.
As of 2026, Google’s index contains hundreds of billions of web pages.
What Indexing Involves
Indexing is not simply storing a copy of the page. It involves analysing and understanding the content so it can be retrieved and ranked for relevant queries. During indexing, Google:
- Identifies the primary topic and subtopics of the page
- Extracts entities (people, places, organisations, products) and their relationships
- Analyses the language and semantic meaning of the content
- Notes the page’s position within the site structure (via internal links and the sitemap)
- Records signals about the page’s quality, authority, and freshness
- Processes any structured data markup on the page
Why Pages May Not Be Indexed
Not every page Google crawls gets indexed. Google may decide not to index a page for several reasons:
Thin content — pages with very little substantive content offer little value and may be excluded from the index.
Duplicate content — if the content on a page is substantially the same as another page on your site or another site, Google may choose to index only one version.
Noindex directives — pages tagged with a “noindex” meta tag or HTTP header are explicitly excluded.
Low quality — Google’s quality assessment systems may determine that a page does not meet a threshold of usefulness.
Canonicalisation issues — if multiple URLs contain the same content, Google will select one canonical URL to index and may ignore the others.
You can check whether your pages are indexed using Google Search Console. If important pages are not appearing in search results, checking their indexing status is always the first diagnostic step.
The Knowledge Graph
Alongside its traditional page index, Google maintains a separate database called the Knowledge Graph. This is a structured database of entities and the relationships between them.
The Knowledge Graph powers many of the instant answers, knowledge panels, and “rich results” you see in search results pages. When you search for a public figure, a company, a film, or a scientific concept, the information panel that appears on the right side of search results (on desktop) is drawn from the Knowledge Graph, not from a traditional web page.
Stage 3: Ranking
Ranking is the process of determining the order in which indexed pages appear in response to a specific search query. This is the most complex stage and the one most closely tied to SEO.
When a user submits a query, Google does not search the live web. It searches its index, retrieves all pages that are potentially relevant to that query, and then scores and orders them using its ranking algorithm.
The Ranking Pipeline
Google’s ranking process is not a single algorithm. It is a layered pipeline of systems that work in sequence. Understanding this pipeline, even at a high level, transforms how you think about SEO.
Step 1: Retrieval. Google pulls a large set of candidate pages from its index that are potentially relevant to the query. This initial retrieval uses a combination of keyword matching and semantic matching to cast a wide net.
Step 2: Pre-scoring. A broad scoring pass evaluates the candidate pages against hundreds of signals, filtering down the results to a more manageable set.
Step 3: Final scoring and ranking. The top candidates go through a deeper, more computationally intensive evaluation, including Google’s AI language systems. The final ranked list is produced here.
Step 4: Twiddlers. A set of re-ranking adjustments are applied to the final list based on specific criteria, such as freshness (prioritising recent content for time-sensitive queries), quality boosts, and user behaviour signals.
Step 5: Personalisation. The results are adjusted based on the individual user’s context, including their location, language, device, and (for logged-in users) search history.
How Google Understands Language: AI Systems in the Ranking Pipeline
For most of SEO’s history, search engines matched keywords. If you searched for “best Italian restaurants London,” Google looked for pages containing those exact words. This approach had obvious limitations — it could not understand meaning, context, or intent.
Today, Google’s ranking pipeline includes multiple AI systems that enable it to understand language at a far deeper level.
Hummingbird (2013) — the shift to meaning. Google’s Hummingbird update was the first significant move away from pure keyword matching. It began processing queries as complete phrases to understand intent, rather than treating each word independently. This is why Google can now understand that “how do I get rid of ants in my kitchen” and “ant removal kitchen” express similar needs.
RankBrain (2015) — handling the unknown. RankBrain was Google’s first deep-learning AI system applied to search ranking. Its primary job is to handle queries Google has never seen before. Approximately 15% of all daily searches are completely new combinations that have never been searched before. RankBrain translates unfamiliar queries into mathematical vectors and finds related known queries to understand what the user is likely looking for. It also interprets user engagement signals to refine its understanding of which results best serve different types of queries.
Neural Matching (2018) — matching concepts, not keywords. Neural Matching analyses entire queries and entire pages as concepts rather than collections of keywords. It can find relevant results even when not a single keyword on the page matches a word in the query, because it works in a multi-dimensional “meaning space” where related concepts cluster together. This is why you can search for a concept in your own words and find relevant results even if the pages use entirely different terminology.
BERT (2019) — understanding context and nuance. BERT (Bidirectional Encoder Representations from Transformers) is a natural language processing model that understands the context of words within a sentence by reading text in both directions simultaneously. Before BERT, Google struggled with sentences where small words changed meaning significantly. The classic example is the word “to” in “Brazilian traveller to USA needs a visa.” BERT understands the direction of travel and returns results about Brazilians travelling to the USA, not Americans travelling to Brazil. When applied to ranking, BERT (internally called DeepRank at Google) analyses the top candidate pages at a deep linguistic level to identify the best matches for a query. Because it is computationally intensive, it is applied only to the final shortlist of candidates.
MUM — the multimodal model. MUM (Multitask Unified Model) is 1,000 times more powerful than BERT by Google’s own account. It can understand and generate language across 75 languages, process images and video alongside text, and handle complex multi-step queries. Importantly, Google has confirmed that MUM is not currently used for general organic search ranking. Its applications are more specific, including understanding complex queries and powering certain knowledge-based features.
The practical implication of all these systems: writing for search engines by stuffing keywords is not only unnecessary in 2026, it actively signals low quality. Google understands natural language. Write for humans, and the algorithm will follow.
Stage 4: Results Generation (The SERP)
The Search Engine Results Page (SERP) is what users see after submitting a query. In 2026, SERPs are far more complex than the simple list of ten blue links that defined search for much of its history.
Types of Results on a Modern SERP
Organic results — the traditional ranked list of web pages. These are what SEO primarily targets.
Paid results — advertisements that appear above and sometimes below organic results. These are clearly labelled as “Sponsored.” Advertisers pay per click.
Featured snippets — a highlighted box that appears above the first organic result for certain queries, displaying a direct answer extracted from a web page. Sometimes called “position zero.”
Knowledge panels — information boxes drawn from the Knowledge Graph, typically appearing for brand, person, or place searches.
Local pack — a map with three local business listings, appearing for queries with local intent (for example, “coffee shop near me” or “dentist in Edinburgh”).
Image pack — a row of images, often appearing for visual queries.
Video results — video thumbnails, usually from YouTube.
People Also Ask — a box of related questions that expand to show brief answers when clicked.
Shopping results — product listings with images, prices, and ratings, appearing for commercial product queries.
Rich results — enhanced organic listings that include additional information such as star ratings, recipe details, event dates, or product availability, powered by structured data markup.
The type of results Google shows for any given query depends entirely on search intent. A query like “how to make pasta” will show mostly video results and recipe cards because Google’s data shows that is what users want. A query like “best pasta recipes” will show a mix of list-style organic results. A query like “buy pasta maker” will show shopping results prominently.
Understanding what result types Google shows for your target keywords is a critical step in any content planning process.
Stage 5: AI Synthesis (The 2026 Layer)
In 2026, a fifth stage sits on top of the traditional pipeline for a growing proportion of queries: AI synthesis.
AI Overviews
AI Overviews are AI-generated answers that appear at the top of Google search results for certain queries, above the traditional organic results. They are generated by Google’s Gemini AI model and synthesise information from multiple web pages into a single, directly readable answer, with citations linking back to the source pages.
Google states that AI Overviews are shown only when its systems determine the AI-generated answer adds value that the traditional results list would not. They do not appear for every query.
AI Mode
AI Mode is a more advanced, dedicated AI search experience that Google began rolling out broadly in 2025 and expanded in 2026. It uses a technique called query fan-out.
Query fan-out — the process by which an AI search system breaks a single complex query into multiple related sub-queries, runs all of them concurrently across subtopics and data sources, then synthesises the results into a comprehensive answer.
For example, if you search “how do I start growing vegetables in a small garden,” AI Mode may simultaneously search for “best vegetables for beginners,” “container gardening techniques,” “soil preparation for raised beds,” and “how much sunlight do vegetables need” — and combine the answers into one response. This allows AI Mode to deliver much greater depth and breadth than a traditional search on a complex topic.
AI Mode also supports follow-up questions within the same session, making the experience more like a conversation than a traditional search.
What AI Search Means for Your Content
Google published its official guide to optimising for AI features in May 2026, which made one thing very clear: optimising for AI search is not a separate discipline from SEO. It is the same discipline applied more rigorously.
The content that gets cited in AI Overviews and AI Mode responses is the same content that ranks well in traditional organic search. Strong E-E-A-T signals, well-structured pages, clear and accurate information, and technical credibility are the common threads.
However, there are specific content qualities that make pages more likely to be cited in AI-generated answers:
- Clear, concise definitions and direct answers near the top of the page
- Content organised into distinct sections with descriptive headings
- Coverage of a topic’s full breadth, not just the top-level keyword
- Factually accurate, verifiable claims
- Structured data markup that helps AI systems extract and identify content precisely
- Consistent and accurate information about your brand across multiple independent sources
One significant practical note: Google confirmed in May 2026 that AI Overviews and AI Mode use query fan-out, which means a single focused, well-scoped section of a page on a specific subtopic can earn a citation even when the overall page does not rank in the top ten organic results for the broader query. This creates new opportunities for content that goes deep on specific aspects of a topic.
How Personalisation Affects Search Results
Search results are not the same for everyone. Google personalises results based on several factors.
Location. Search results vary significantly by geography. A search for “best pizza” in Manchester returns different results than the same search in Melbourne. Location is inferred from your IP address and, for mobile users, your device’s GPS.
Language. Google returns results in the language it determines the user speaks, based on their browser settings, location, and search history.
Device type. Results on mobile devices differ from desktop results in layout and sometimes content. Google uses mobile-first indexing, meaning it primarily uses the mobile version of your site to determine rankings for all devices.
Search history (for signed-in users). For users signed into a Google account, past searches and browsing behaviour can influence result personalisation, though Google has reduced the extent of this personalisation over time.
SafeSearch settings. Users with SafeSearch enabled see filtered results that exclude explicit content.
The practical implication for SEO: when you check your keyword rankings, try to do so using tools designed to show objective rankings rather than checking from your own browser, where your search history may inflate how well your pages appear to rank.
Other Search Engines
While Google dominates global search, understanding the broader landscape matters, especially if your audience is in regions where other engines have significant share.
Bing — Microsoft’s search engine, which also powers Yahoo Search. Bing holds roughly 3 to 4% of global search but a higher share in the United States. Bing has integrated Microsoft Copilot, its AI-powered answer system, directly into search. The ranking signals Bing uses are broadly similar to Google’s, with some differences in how it weights social signals and domain authority.
Baidu — the dominant search engine in China, holding over 60% of the Chinese search market. Baidu’s algorithm and optimisation requirements differ significantly from Google’s, and SEO for Baidu requires a separate strategy including Chinese-language content and compliance with Chinese internet regulations.
Yandex — the leading search engine in Russia. Like Baidu, it requires a distinct optimisation approach for businesses targeting Russian-speaking users.
DuckDuckGo — a privacy-focused search engine that does not track users or personalise results. It uses a combination of its own crawl and Bing’s index for results.
AI-first search engines — tools like Perplexity and ChatGPT Search function increasingly like search engines, retrieving and summarising information from the web. These systems draw primarily from high-authority, well-structured, indexable web content, which means strong foundational SEO remains the best investment for visibility across all of these platforms.
Google Algorithm Updates: Why Rankings Change
Google updates its search algorithm thousands of times each year. Most updates are small and go unnoticed. But several times a year, Google releases significant core updates that can cause substantial ranking changes across many websites.
Major Historical Updates
Panda (2011) — targeted low-quality, thin, and duplicate content. Sites that had grown their traffic through volume of low-quality pages saw dramatic ranking drops.
Penguin (2012) — targeted manipulative link-building practices, particularly sites that had acquired large numbers of low-quality or spammy backlinks.
Hummingbird (2013) — introduced semantic search and intent understanding, as covered earlier in this guide.
Mobilegeddon (2015) — introduced mobile-friendliness as a ranking signal, penalising sites that delivered poor experiences on smartphones.
RankBrain (2015) — introduced AI-powered query interpretation.
Medic Update (2018) — placed greater emphasis on E-E-A-T signals, particularly for health and financial content (YMYL sites).
BERT (2019) — improved natural language understanding in query interpretation and ranking.
Helpful Content System (2022 onwards) — a sitewide signal that targets content created primarily to rank in search rather than to genuinely help users. Sites with significant amounts of unhelpful content see ranking suppression across their entire domain, not just on the poor pages.
Core updates (ongoing) — Google releases broad core updates several times a year that recalibrate its overall quality assessment. These can cause significant ranking movements in either direction.
What to Do When Rankings Drop
If your site experiences a ranking drop following a Google algorithm update, the first step is to diagnose whether it is a core update, a targeted update (like a spam update), or a separate technical issue.
Core updates typically reward sites that demonstrate genuine expertise and usefulness, and suppress sites that do not. If your site is affected by a core update, the solution is not a quick technical fix. It is a longer-term investment in content quality, author expertise, and genuine usefulness to your audience.
What This All Means for SEO
Understanding how search engines work makes SEO strategy considerably clearer. Here are the most important practical implications.
Create content for humans, not algorithms. Google’s AI systems are sophisticated enough to understand natural language, detect thin or unhelpful content, and measure how users actually engage with pages. The single most consistent piece of advice across every Google update and guideline is this: make pages that are genuinely useful for the people searching for them.
Technical foundations must be in place. Even the best content cannot rank if it cannot be crawled and indexed. Site speed, mobile-friendliness, crawlability, and HTTPS are not optional extras. They are prerequisites.
Search intent comes before keywords. Before writing any piece of content, understand what the person searching that term actually wants: information, a product, a local service, a comparison? The format and depth of your content must match that intent, or it will not rank regardless of how well it is written.
Authority is earned, not declared. Search engines assess authority through the behaviour of other websites (backlinks) and the signals of genuine expertise within your content. You cannot tell Google you are an authority. You have to demonstrate it through consistent, high-quality, well-cited, experience-backed content over time.
AI search rewards depth and structure. For AI Overviews and AI Mode, content that is organised into clear, extractable sections covering a topic’s full depth is more likely to be cited. A single well-written paragraph on a specific subtopic can earn an AI citation even without a top-ten organic ranking for the broader keyword.
Rankings are not the only metric. In 2026, appearing as a cited source in an AI Overview or AI Mode answer can drive significant visibility even without a traditional high organic ranking. Monitoring brand mentions and AI citation frequency is becoming as important as tracking keyword positions.
❓ Frequently Asked Questions
How long does it take for Google to index a new page?
It varies significantly. A new page on an established, frequently crawled website can be indexed within hours or days. A page on a new website with few backlinks may take weeks or months. Submitting your XML sitemap to Google Search Console and using the URL Inspection tool to request indexing can speed up the process.
Why does my website not appear in Google?
The most common reasons are that Google has not yet crawled it, the page is blocked by robots.txt, a noindex tag is present on the page, the content is too thin to merit indexing, or the site is too new and has no links pointing to it. Google Search Console is the essential diagnostic tool for investigating indexing issues.
Does Google index all pages on my website?
Not necessarily. Google makes judgements about which pages on your site are worth indexing based on quality, uniqueness, and crawl budget. Low-quality, duplicate, or thin pages may be crawled but not indexed.
Can I see how often Googlebot crawls my site?
Yes. Google Search Console provides crawl statistics showing how many pages Googlebot visits each day, which types of requests it makes, and how your server responds.
Why do different people see different search results?
Because Google personalises results based on location, device, language, and (for signed-in users) past search behaviour. Two people in different cities searching the same term may see meaningfully different results, especially for queries with local intent.
Does social media affect search rankings?
Social media signals are not confirmed direct ranking factors for Google. However, content that spreads on social media tends to earn more backlinks and visibility, which do affect rankings. The indirect relationship is real, even if social shares are not counted as direct votes.
How is Bing different from Google for SEO?
The fundamentals are similar: quality content, backlinks, and technical health matter on both. Bing places somewhat more weight on exact-match keywords and social signals than Google. Bing Webmaster Tools is the equivalent of Google Search Console for monitoring your Bing presence.
Summary
Search engines work through four core stages: crawling (discovering content), indexing (storing and understanding it), ranking (determining order for each query), and results generation (displaying those results on the SERP). In 2026, a fifth AI synthesis stage now generates direct answers for a growing share of queries.
The most important things to understand:
- Crawlers follow links to discover content. Pages with no links pointing to them are invisible to search engines.
- Indexing is about understanding, not just storing. Google analyses content, entities, and quality signals when it indexes a page.
- Ranking is a multi-layered pipeline, not a single algorithm. AI systems like RankBrain, Neural Matching, and BERT allow Google to understand meaning and intent, not just keywords.
- Query fan-out in AI Mode means a well-structured, specific section of a page can earn visibility even beyond its traditional organic ranking position.
- Personalisation means your results are not universal. Location, device, and user history all shape what people see.
- Every Google algorithm update is a recalibration toward the same goal: surfacing the most genuinely helpful content for the user. The best long-term SEO strategy is to make that goal easy for Google to achieve on your site.



