Knowledge Graph: The Complete Guide to Entities, Relationships, and Search Understanding
Learn how search engines and AI systems connect entities, build knowledge graphs, and use relationships to understand people, brands, organizations, products, and topics.

What Is a Knowledge Graph?
A knowledge graph is a structured network of entities and the relationships between them. It is not a list of facts. It is a map of how things connect to each other, stored in a way that lets a machine reason across those connections rather than just retrieve individual records.
The three building blocks of any knowledge graph are simple: entities (the things), attributes (the properties of those things), and relationships (how those things connect to each other). Together, these three elements let a system answer not just “what is this?” but “how does this relate to everything else I know?”
A few examples of how knowledge graph relationships look in practice:
Each of those arrows is a relationship. A knowledge graph is, at its core, a very large, very structured network of relationships like these, covering millions of entities across every topic a search engine or AI system needs to understand.
It is also worth being clear about what a knowledge graph is not. It is not exclusively Google’s product. The concept predates Google’s implementation and is used across search engines, AI systems, academic databases, and enterprise software. Google’s Knowledge Graph (launched in 2012, to the best of my knowledge) is the most publicly discussed, but Wikidata, DBpedia, Freebase (now largely absorbed into Wikidata), and others all operate on the same principles and feed into how various AI systems understand the world.
Why Knowledge Graphs Matter
Knowledge graphs matter because they allow machines to understand meaning, not just match text. This affects four areas directly relevant to search and AI visibility.
Search engines
A search engine using a knowledge graph can understand that a query about “the founder of Visiblytics” is asking about a specific person connected to a specific organization, not just looking for pages that contain those words. This is what enables direct answers, entity-based results, and intent understanding rather than pure keyword matching.
AI systems
Conversational AI tools like ChatGPT, Gemini, Claude, and Perplexity reason about the world using structured knowledge, including knowledge graph data, to construct accurate answers. When someone asks an AI who founded a company, what a brand does, or who the recognized experts in a field are, the AI is drawing on structured entity and relationship data, not just scanning text for keyword matches. A brand or individual that is well-represented in that structured knowledge is more likely to appear in those answers.
Knowledge panels
Knowledge panels, the structured information boxes that appear in Google Search when you search for a recognized entity, are built from knowledge graph data. They are a visible symptom of knowledge graph inclusion, not a separate system. The connection between knowledge graphs and knowledge panels is covered in more depth in the Knowledge Panel guide.
AI Visibility
As covered in the AI Visibility guide, AI systems use knowledge graphs as one of their core mechanisms for verifying entities and cross-referencing claims. A strong knowledge graph presence is one of the most durable signals that an AI system can draw on when deciding whether a source is trustworthy and worth citing.
Knowledge Graph Components
Every knowledge graph, regardless of scale or implementation, is built from the same four components. Understanding them is what separates a vague idea of “being in the knowledge graph” from a concrete understanding of what you are actually trying to build.
Entities
Entities are the nodes in the graph: the real, distinct, identifiable things the graph stores information about. These are the same entities covered in the Entity SEO guide: people, organizations, places, products, and concepts.
In a knowledge graph, each entity has a unique identifier so the system can distinguish between two different entities that share a name. “Mercury” the planet and “Mercury” the element are different nodes, connected to different attributes and different relationships, even though they share a label.
Attributes
Attributes are the properties that describe an entity. They answer the question: what do we know about this thing?
For a business entity, attributes might include:
Attributes are what get surfaced in a knowledge panel, what AI systems draw on when describing a brand, and what distinguish one entity from another entity with similar characteristics. The more accurately and completely your attributes are represented across credible sources, the more confidently a knowledge graph can describe you.
Relationships
Relationships are the edges in the graph: the connections between entities. They are what make a knowledge graph fundamentally different from a list of facts. A list of facts about Suraj Saini and a list of facts about Visiblytics are two separate pieces of information. The relationship “Suraj Saini founded Visiblytics” connects those two nodes into a network that a machine can reason across.
Relationships have direction and type. “Founded” is a different relationship from “works at,” which is different from “invested in.” The specificity of relationship types is part of what makes knowledge graphs useful for answering nuanced questions rather than just retrieving entity descriptions.
Context
Context is the layer that gives relationships meaning within a broader network. It is what allows a knowledge graph to distinguish between two entities that have a similar relationship to a third entity, or to understand that a relationship relevant in one domain may not apply in another.
Context in a knowledge graph is built from the surrounding network of entities and relationships, the sources that corroborate those relationships, and the consistency with which those relationships appear across independent sources. This is why third-party mentions, citations from authoritative sources, and Wikidata entries all contribute to knowledge graph strength: they are the raw material from which context is established.
How Knowledge Graphs Work
A knowledge graph doesn’t assemble itself automatically from your website. It is built through a process that begins with content and ends with structured knowledge stored in a way that enables machine reasoning.
A crawler reads your page, a third-party mentions your brand, or a structured data source (like Wikidata) is processed.
As covered in the Entity SEO guide, named entity recognition identifies the real-world things referenced in that content: the specific organization, person, or product being discussed.
Beyond identifying entities, the system identifies the relationships between them. “Suraj Saini founded Visiblytics” is a relationship. “Visiblytics publishes content about Entity SEO” is a relationship. These are detected from content, from structured data (schema markup), and from corroborating sources.
When an entity and its relationships are sufficiently well-corroborated across independent sources, the system has enough confidence to include that entity in its structured knowledge. This is not an automatic result of having good schema or an entity homepage: those are inputs that make corroboration possible, not guarantees of inclusion.
Once in the knowledge graph, an entity becomes part of the structured network that search engines and AI systems reason across. Queries that involve your entity, your relationships, or your area of expertise can now be answered using structured knowledge about you, not just keyword-matched pages about you.
Knowledge Graph vs. Database
Many people use “knowledge graph” and “database” interchangeably. They are not the same thing, and the distinction matters for understanding why knowledge graphs are particularly powerful for search and AI applications.
| Traditional Database | Knowledge Graph |
|---|---|
| Stores records | Stores relationships |
| Rows and columns | Nodes and edges |
| Data retrieval | Meaning retrieval |
| Fixed schema | Flexible, extensible structure |
| Answers “what is this record?” | Answers “how does this relate to everything else?” |
| Optimized for lookup | Optimized for reasoning |
A traditional database stores a row for Visiblytics with columns for industry, location, and founding date. To find the connection between Visiblytics and Suraj Saini, you’d query a separate table and join the results.
A knowledge graph stores Visiblytics and Suraj Saini as connected nodes, with “Founded” as the edge between them. A query like “who founded this company” doesn’t require a join: it traverses the relationship directly. And from that starting point, it can traverse further: what else did this founder create, what topics does this company cover, what other entities is it connected to?
This is why knowledge graphs are the natural data structure for AI systems that need to answer complex, multi-hop questions rather than just look up individual records.
Knowledge Graphs and Entity SEO
Entity SEO and knowledge graphs are two distinct disciplines that work in sequence. Entity SEO identifies entities. Knowledge graphs connect them.
Without Entity SEO, a knowledge graph has nothing reliable to work with. An entity that is inconsistently named, poorly attributed, and unverified across independent sources is a weak candidate for knowledge graph inclusion because the system cannot confidently resolve it to a single, specific entity.
With Entity SEO in place, the raw materials for knowledge graph inclusion exist: a clearly named entity, consistent attributes, machine-readable schema, and an entity homepage that serves as the source of record. The Entity SEO guide covers how to build all of these in detail, including the full Entity Building Roadmap from entity identification through to knowledge panel eligibility.
One important clarification: having good Entity SEO does not guarantee knowledge graph inclusion. It is a necessary condition, not a sufficient one. The knowledge graph also requires corroboration from sources outside your own domain, which is why external mentions, Wikidata entries, and third-party citations are part of the building process.
Knowledge Graphs and Knowledge Panels
A knowledge panel is what becomes visible in search results when a search engine has included your entity in its knowledge graph with sufficient confidence. The relationship is direct, but it is not automatic.
The important word in that chain is “eligibility.” Knowledge graph inclusion does not guarantee a knowledge panel. I am not certain of the exact confidence thresholds or criteria Google uses to decide when to display a knowledge panel for a given entity, and Google hasn’t published a precise breakdown of this. What is clear is that knowledge panels tend to appear for entities with strong, consistent, well-corroborated knowledge graph representation.
What this means practically: building knowledge graph presence is the right goal. A knowledge panel, if and when it appears, is a visible confirmation that the work has reached a meaningful threshold. It is not the target in itself.
A full guide to Knowledge Panel development covers this distinction in depth.
Knowledge Graphs and AI Visibility
AI systems use structured knowledge, including knowledge graph data, as one of the core inputs for constructing accurate answers. This is the link between knowledge graph work and the broader goal of AI Visibility.
When ChatGPT, Gemini, Claude, or Perplexity answer a question that involves your brand, your expertise, or your area of focus, they are drawing on structured knowledge that includes knowledge graph data where it is available. An entity that is clearly defined in a knowledge graph is easier for an AI system to represent accurately, easier to cite with confidence, and less likely to be confused with another entity or omitted entirely.
This is why knowledge graph work is Pillar 2 in the AI Visibility framework, sitting directly above Entity SEO and directly below Knowledge Panel development. It is the connective layer that turns isolated entity definitions into a structured network an AI system can reason across.
It is worth being precise here: I cannot tell you exactly how much weight any individual AI company places on knowledge graph data in their citation selection, since OpenAI, Google, Anthropic, and Perplexity have not published that detail. What is established is that these systems are built to reason about entities and relationships, and that well-structured entity data in credible sources feeds into that reasoning.
How to Build a Strong Knowledge Graph Presence
Building knowledge graph presence is not a single action. It is the outcome of a sequence of steps done well and maintained over time. Several of these steps overlap with the Entity Building Roadmap covered in the Entity SEO guide, so rather than repeating that full roadmap here, this section focuses on what specifically matters at the knowledge graph layer.
Your organization needs a structured, factual page that functions as its source of record: consistent naming, clear attributes, Organization schema, and links to verified external profiles. Key individuals publishing content on your site need author pages with Person schema. These are the pages that crawlers use as the primary anchor for your entity. The structure and content of entity homepages is covered in detail in the Entity SEO guide.
Schema markup is the machine-readable layer that makes your entity’s attributes and relationships explicit rather than inferred. Organization schema, Person schema, and Article schema are the three most directly relevant for knowledge graph purposes. The Schema Markup Generator handles the technical implementation, and the Structured Data Testing Tool confirms it is error-free. Schema does not put you in a knowledge graph on its own, but it removes ambiguity that would otherwise slow or prevent inclusion.
Relationships need to be both stated and corroborated. State them through schema (sameAs, founder, author, memberOf references) and through clear on-page content. Corroborate them by ensuring that the same relationships are visible on external sources: your LinkedIn profile showing your company affiliation, your company website linking to your author page, third-party articles mentioning you in your professional capacity. Relationships that exist only on your own site carry less weight than relationships visible across multiple independent sources.
Knowledge graphs resolve ambiguity partly by looking for consistency across sources. If your brand name, your location, your founder’s name, or your area of focus appears differently across your site, your schema, your social profiles, and third-party mentions, the system has to decide which version to trust. Every inconsistency is a small tax on your entity’s clarity. This is particularly important when information changes: if your company evolves its focus, update all sources, not just your homepage.
Third-party corroboration is the most important input for knowledge graph inclusion that you cannot manufacture directly. A mention of your brand in a credible publication, a citation in an industry directory, an entry in Wikidata, a reference in a recognized organization’s member list: these are the signals that tell a knowledge graph system your entity is real, recognized, and worth including. Wikidata is worth specific attention here because it is a structured, open knowledge base that feeds directly into several knowledge graph systems and has lower barriers to entry than Wikipedia.
Original content, particularly research, data, or analysis that doesn’t exist elsewhere, gives knowledge graph systems new facts to associate with your entity. It also creates natural opportunities for third-party citations, which is the external corroboration that Step 5 depends on. Thin content or purely derivative content adds nothing to knowledge graph strength because it introduces no new entity-associated facts.
Common Knowledge Graph Mistakes
These are the patterns that most consistently prevent brands from building meaningful knowledge graph presence:
❌ No entity homepage
Publishing content without a structured entity page leaves your organization without a credible, machine-readable source of record. A knowledge graph system encountering your brand for the first time has no reliable anchor from which to build its representation of you.
❌ Weak or missing schema
Writing factually rich content about your entity without backing it with schema means relying on a crawler’s ability to infer your entity’s attributes from prose alone. Schema removes that ambiguity explicitly. No schema means slower, less reliable entity recognition.
❌ Inconsistent branding across sources
Using different versions of your brand name, different descriptions of your services, or different job titles for key people across your website, social profiles, and third-party mentions makes disambiguation harder. The knowledge graph has to decide which version of your entity is the authoritative one.
❌ Missing author entities
Publishing content under anonymous or thin author accounts strips your content of person-entity associations. Search engines and AI systems increasingly weight author identity when evaluating content credibility. An author with no verifiable entity profile contributes less to knowledge graph strength than one with a complete, consistent, and well-corroborated person entity.
❌ No relationship mapping
Having an entity page and schema but failing to connect entities to each other (author pages not linked to articles, Organization schema not referencing founders, content not internally linked to topic clusters) leaves relationships implicit. Implicit relationships are far weaker knowledge graph inputs than explicit ones.
❌ Duplicate or conflicting entity information
Multiple pages on your site that describe your organization differently, or an old website still ranking alongside a new one with different entity details, create conflicting signals. A knowledge graph system encountering contradictory information about what should be the same entity may lower its confidence in that entity’s representation.
Knowledge Graph Examples
Knowledge graphs are easiest to understand through concrete examples of the relationships they store. None of the examples below requires a formal knowledge graph entry to be valid: they are illustrations of the relationship structure that knowledge graphs are built to represent. All examples use entities that are unambiguously recognized across every major knowledge graph system.
The multi-hop example illustrates why knowledge graphs are particularly powerful for AI systems: complex, connected questions can be answered by traversing relationships rather than matching keywords across separate pages.
How Knowledge Graphs Appear in Search
Knowledge graphs are invisible infrastructure. You cannot see a knowledge graph directly. What you can see are the search features it powers, the most visible of which is the knowledge panel.
When you search for “Steve Jobs” or “Google” in Google Search, the information box that appears on the right side of the results (on desktop) or at the top of the results (on mobile) is a knowledge panel. It displays the entity’s name, description, key attributes, and related entities in a structured, summary format.
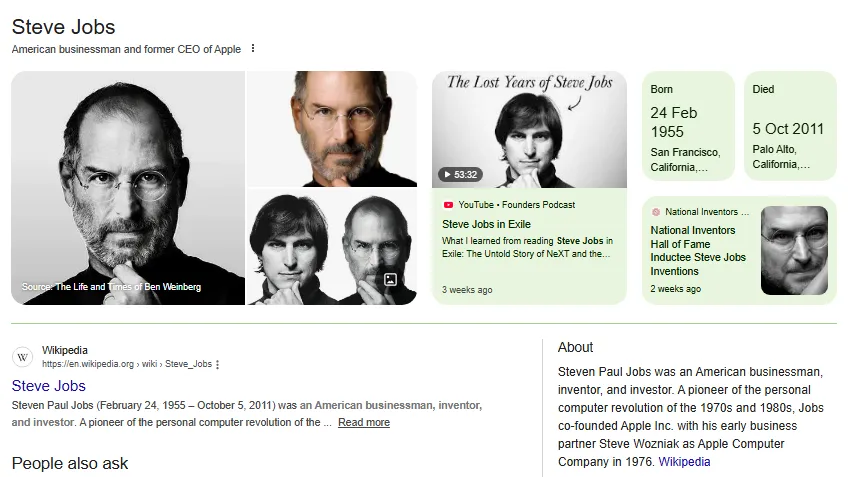
Google search for “Steve Jobs” showing the knowledge panel with name, photo description, birth date, role, and associated entities like Apple and Pixar.
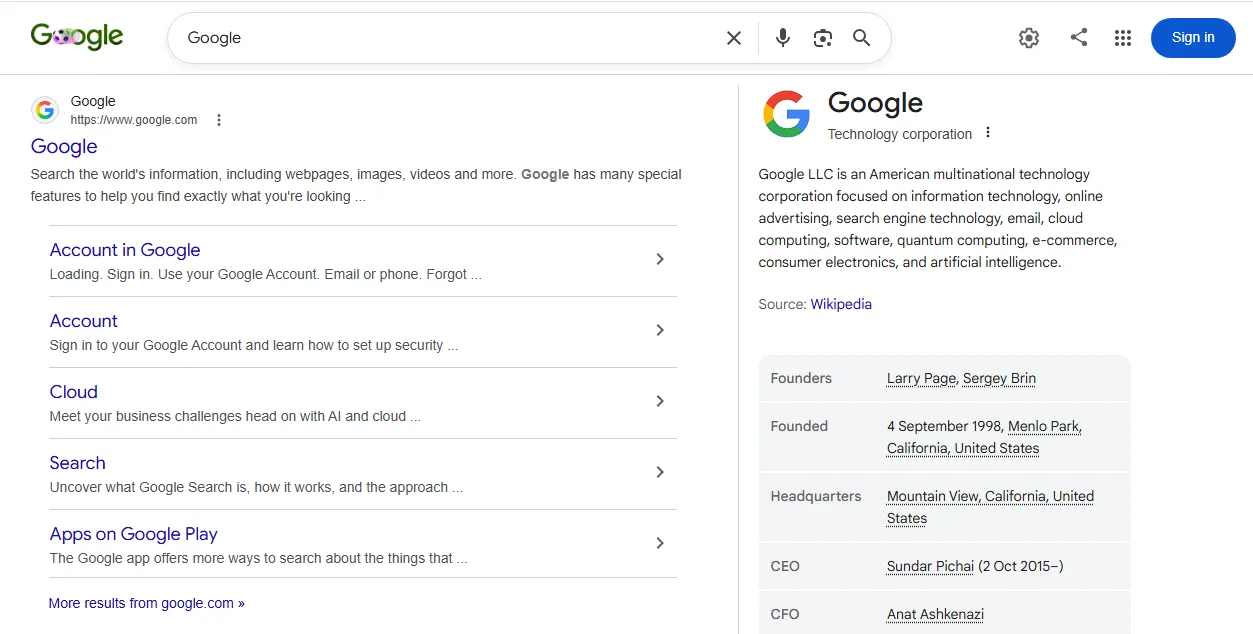
Google search for “Google” showing the organizational entity’s description, founder names, and key products.
A knowledge panel is not the knowledge graph. It is one visible output that a knowledge graph can produce under the right conditions. The distinction is important enough that it deserves its own section.
Knowledge Graph vs. Knowledge Panel
This is one of the most commonly confused distinctions in Entity SEO and search visibility. They are related but they are not the same thing, and treating them as interchangeable leads to misaligned goals.
| Knowledge Graph | Knowledge Panel |
|---|---|
| The underlying data structure | A visible search feature |
| Stores entities and relationships | Displays summarized entity information |
| Invisible to the end user | Visible in search results |
| The foundation | The output |
| Built from many sources over time | Generated when confidence threshold is met |
| Cannot be directly requested | Cannot be directly created |
| Affects all search and AI understanding | Affects branded search appearance |
The practical implication: you cannot build a knowledge panel directly. You build knowledge graph presence, and a knowledge panel may appear as a result. Many entities are well-represented in a knowledge graph and never develop a knowledge panel because they haven’t crossed whatever confidence threshold triggers the panel display. I’m not certain of the exact threshold, since Google hasn’t published the precise criteria.
What this means for your strategy: optimizing for knowledge graph presence is the correct goal. It improves search understanding, AI citations, and entity recognition across every surface, not just the presence or absence of a knowledge panel. The panel, if it appears, is a useful confirmation. It is not the measure of success.
A full treatment of knowledge panel development, including how to claim and correct panels when they do appear, is in the Knowledge Panel guide.
Knowledge Graph Sources
Most people building entity presence ask the same practical question: where does a knowledge graph actually get its information? The answer is that knowledge graphs draw from multiple source types, and the combination of corroboration across those sources is what builds entity confidence.
Website content
A crawlable, well-structured website with clear entity information is a primary input. Pages that describe your organization, your people, and your products in factual, consistent language give crawlers entity-attributable content to work with.
Structured data
Schema markup is the most direct input you control. Organization schema, Person schema, and Article schema explicitly declare your entity’s name, attributes, and relationships in machine-readable format, removing the ambiguity that prose alone leaves open. The Schema Markup Generator and Structured Data Testing Tool are the right tools for this layer.
Author pages
Dedicated, factual author pages associated with published content create person-entity anchors. A byline connected to a real, verifiable person entity carries significantly more weight than anonymous or thin author attribution.
Social profiles
Consistent, complete profiles on LinkedIn, Twitter/X, and other platforms provide third-party corroboration of your entity’s existence and attributes. Schema sameAs references that link from your site to these profiles explicitly connect them to your entity definition.
Wikidata
Wikidata is an open, structured knowledge base that feeds directly into multiple knowledge graph systems. A well-maintained Wikidata entry for your organization and key individuals is one of the highest-value external entity signals available to most businesses, with lower barriers to entry than Wikipedia.
Organization profiles
Industry directories, professional associations, government business registries, and credible listing sites provide structured, third-party entity corroboration that knowledge graph systems treat as independent verification.
Trusted publications
Coverage in credible publications, particularly those that already have strong entity representation in knowledge graphs, creates mention-based corroboration. An article in a recognized publication that names your brand and describes what it does is an entity signal, even without a link.
The common thread across all these sources: knowledge graphs favor corroboration. A fact about your entity that appears in one place is a data point. The same fact appearing consistently across your own site, your structured data, your social profiles, a Wikidata entry, and third-party publications is a corroborated signal. The more sources agree, the more confident the knowledge graph can be.
Future Knowledge Graph Resources
The following concepts will each receive standalone treatment as the Visiblytics resource library grows. They are listed here as a map of where this subject goes:
Wikidata for SEO
how to create and maintain a Wikidata entry and why it matters for knowledge graph inclusion
coming soonSchema and Knowledge Graphs
how specific schema types map to knowledge graph components
coming soonKnowledge Graph APIs
how structured knowledge graph data is accessed and used by AI systems
coming soonEntity Relationships in Depth
relationship types, directionality, and how to make them machine-readable
coming soonKnowledge Graph SEO
a practical framework for auditing and improving knowledge graph presence
coming soonKnowledge Graph Audits
how to evaluate your current knowledge graph representation and identify gaps
coming soonOnce this library grows, each will be linked here directly.
Frequently Asked Questions
A knowledge graph is a structured network of entities and the relationships between them. It stores not just facts about individual things, but the connections between those things, in a form that lets a machine reason across the network rather than just retrieve isolated records. Search engines and AI systems use knowledge graphs to understand meaning, resolve ambiguity, and answer questions that require connecting multiple entities.
Yes. Google has publicly acknowledged the existence of its Knowledge Graph, which it uses to power features like knowledge panels, entity-based search results, and AI Overviews. To the best of my knowledge, Google launched its Knowledge Graph in 2012, though you may want to verify current details about how it functions since Google has continued to develop it and hasn’t published a comprehensive public specification of its current architecture.
A knowledge graph works by storing entities as nodes and relationships as edges connecting those nodes. When a search engine or AI system processes a query, it can traverse the graph: starting from one entity, following relationships to connected entities, and using the network structure to construct an answer. The process of building the graph begins with content and structured data, proceeds through entity recognition and relationship detection, and results in a structured representation that can be queried in ways a traditional keyword index cannot support.
No. A traditional database stores records in rows and columns and is optimized for data retrieval. A knowledge graph stores entities and relationships as nodes and edges and is optimized for meaning retrieval and reasoning. The distinction matters because a database can tell you what attributes an entity has, but a knowledge graph can tell you how that entity relates to everything else in the network.
Knowledge graphs affect SEO by enabling search engines to understand the meaning behind queries rather than just matching keywords, which improves how accurately your entity is surfaced for relevant searches. They also enable entity-based features like knowledge panels and direct answers that increase visibility beyond a standard ranked result. I cannot give you a precise breakdown of how much weight knowledge graph representation carries as a ranking factor, since search engines don’t publish that detail, but the structural role of knowledge graphs in modern search is well established.
Yes. AI systems use structured knowledge, including knowledge graph data, as an input for constructing accurate answers. An entity that is clearly defined and well-corroborated in a knowledge graph is easier for an AI system to represent accurately, easier to cite with confidence, and less likely to be omitted or misrepresented in AI-generated answers. The full chain from knowledge graph to AI Visibility is covered in the AI Visibility guide.
Yes, though the timeline and path depend on your industry, your starting point, and the level of genuine third-party corroboration you can build. The technical groundwork (entity homepage, schema, consistent naming) is achievable for any business regardless of size. The external corroboration (third-party mentions, Wikidata entries, directory presences) takes longer and requires genuine credibility-building rather than technical shortcuts. Small businesses with clear topical focus and genuine expertise in a niche often have an easier path to knowledge graph clarity than large brands trying to claim authority across broad topic areas.
A knowledge graph is the underlying structured database of entities and relationships. A knowledge panel is a visible feature in Google Search results that displays summarized entity information. Knowledge panels are built from knowledge graph data, but knowledge graph inclusion does not automatically produce a knowledge panel. A panel appears when a search engine has sufficient confidence in an entity’s representation to display it prominently for branded searches. The knowledge graph is the cause; the knowledge panel is one possible effect.
Entity SEO Identifies. Knowledge Graphs Connect.
If there is one idea this page should leave you with, it is the distinction in that sentence.
Entity SEO is the work of making your entity clear, consistent, and machine-readable. The Entity SEO guide covers that work in full. Knowledge graphs are what happens next: once entities are identified, they are connected to each other through relationships, stored in a structured network, and made available for search engines and AI systems to reason across.
A brand that has done Entity SEO correctly is a well-defined node. A brand that has also built knowledge graph presence is a well-connected node, part of a network rather than an isolated data point. That difference is what determines whether a search engine or AI system can do something useful with what it knows about you, or whether it knows only a fragment of your story with no way to connect it to the broader picture.
The next step in the architecture is Knowledge Panel development, which covers what happens when knowledge graph representation reaches the threshold where a search engine is confident enough to display your entity publicly in search results.