Knowledge Panel: The Complete Guide to Google’s Entity Panels
Learn how Knowledge Panels work, how they relate to entities and knowledge graphs, and how organizations, brands, and individuals can strengthen their eligibility.

What Is a Knowledge Panel?
A Knowledge Panel is an information box that appears in Google Search results when someone searches for a recognized entity. It surfaces directly in the results page, typically on the right side on desktop and at the top of results on mobile, and displays structured information about that entity without requiring the user to click through to any website.
A Knowledge Panel is not a search ranking. It is not an advertisement. It is Google’s structured summary of what it knows about a specific, verified entity, drawn from its knowledge graph and presented as a consolidated snapshot. It is one of the clearest public signals that Google has confidently identified and verified something as a distinct, real-world entity.
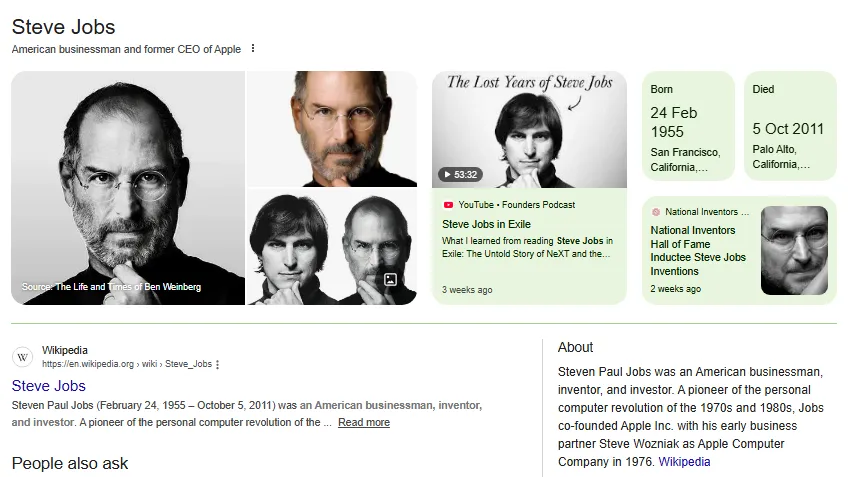
Google search for “Steve Jobs” showing the full Knowledge Panel with his name, description, birth and death dates, roles (co-founder of Apple, Pixar, NeXT), associated entities, and related searches.
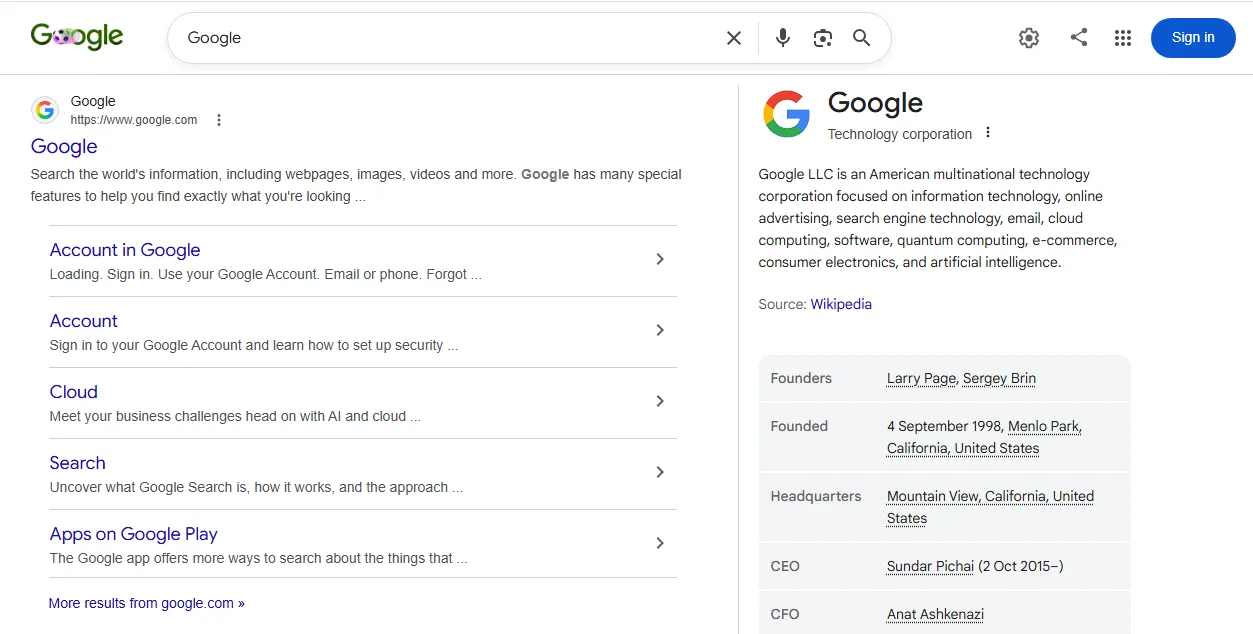
Google search for “Google” showing the organization name, description, founding date, founders (Larry Page, Sergey Brin), headquarters location, CEO, and subsidiaries.
What both panels share: they are built from structured entity data, not from a single webpage. They represent Google’s synthesis of what it has learned about that entity from multiple corroborated sources.
Knowledge Panel vs. Knowledge Graph
The most common confusion in this subject is treating the Knowledge Panel and the Knowledge Graph as the same thing. They are not. The Knowledge Graph guide covers the distinction in full detail, but because it is foundational to understanding Knowledge Panels specifically, here is the core comparison:
| Knowledge Graph | Knowledge Panel |
|---|---|
| Underlying data system | Search feature |
| Stores entities and relationships | Displays entity information |
| Invisible to users | Visible in search results |
| The foundation | The output |
| Built from many sources over time | Generated when confidence threshold is met |
| Affects all search and AI understanding | Affects branded search appearance |
| Cannot be directly seen | Can be seen, claimed, and corrected |
The practical takeaway: you do not optimize for a Knowledge Panel directly. You build knowledge graph presence, and a Knowledge Panel may appear as a result. A brand that focuses on “getting a Knowledge Panel” without building the underlying entity foundation is working backward. The panel is a symptom of strong entity work, not a goal you can pursue in isolation.
How Knowledge Panels Work
A Knowledge Panel appears at the end of a process, not the beginning of one. Understanding the full chain explains why certain optimization efforts produce panels and others do not.
At each step in this chain, Google is asking a version of the same question: how confident am I that I know exactly what this entity is, what it does, and how it relates to other things I already know?
Entity SEO (covered in the Entity SEO guide) answers that question at the definitional level: who is this, what are their attributes, and are those attributes consistent and machine-readable?
The Knowledge Graph (covered in the Knowledge Graph guide) answers it at the relational level: how does this entity connect to other entities I already recognize and trust?
The Knowledge Panel appears when both of those questions have been answered with enough confidence. I am not certain of the exact threshold Google uses, since this hasn’t been published. What is clear is that panels are more likely when entity definition, relationship mapping, and external corroboration are all strong.
Why Knowledge Panels Matter
A Knowledge Panel matters because it changes how your entity is perceived at the exact moment someone is deciding whether to trust you. It surfaces trust signals before the user clicks anything.
Trust
A Knowledge Panel signals that Google has verified your entity as real and recognized. For a user who doesn’t know your brand yet, seeing a structured panel in search results communicates institutional recognition in a way that a standard ranked result cannot. The presence of a panel answers the implicit question “is this a real, legitimate organization?” before it is even asked.
Visibility
A Knowledge Panel occupies significant real estate on the search results page, particularly on mobile where it can dominate the above-the-fold experience. For branded searches, this means your entity information is the first thing a searcher sees, with no competitor content competing for attention in that space.
Brand recognition
The panel reinforces your entity’s key attributes: your description, your category, your key people, your social profiles. Every time a panel appears for a branded search, it is Google presenting a consistent, structured summary of your identity. This consistency compounds over time and contributes to how both people and AI systems understand what your brand represents.
AI Visibility
As covered in the AI Visibility guide, AI systems use structured entity data as a core input for constructing accurate answers. A Knowledge Panel is a visible confirmation that your entity is represented in structured knowledge at a level AI systems can draw from. Brands with strong Knowledge Panel presence are more likely to be cited accurately and confidently by conversational AI tools.
Who Can Get a Knowledge Panel?
Not every entity qualifies for a Knowledge Panel, and not every entity that qualifies will automatically receive one. The threshold is not publicly defined by Google with precision. What is established is that panels appear across a wider range of entity types than most people assume.
People
Public figures, executives, authors, researchers, journalists, academics, musicians, athletes, and other individuals with a meaningful and verifiable public presence are candidates. A person entity typically needs a demonstrated record of notable work and third-party coverage. Being mentioned once in a publication is not sufficient. Having a consistent body of verifiable work, a clear professional identity, and independent coverage of that identity across credible sources is what moves a person entity toward panel eligibility.
Organizations
Companies, nonprofits, government bodies, universities, media outlets, and other organizations are among the most common Knowledge Panel subjects. An organization entity benefits from a clear category, consistent naming across web properties, verifiable founding information, and named individuals (founders, leadership) who are themselves recognized entities.
Brands
Consumer brands, product lines, and software products can have their own panels distinct from their parent company. The brand needs to be clearly defined as a separate entity with its own attributes and recognition.
Places
Cities, countries, landmarks, neighborhoods, and physical locations typically have Knowledge Panels by default given their inherent recognizability. Local businesses can develop panels through Google Business Profile, which operates on related but somewhat distinct principles from the broader knowledge graph.
Concepts
Widely recognized concepts, events, and creative works (films, books, albums) can also generate Knowledge Panels when they are sufficiently well-defined and well-documented in structured sources.
The common denominator across all categories: a Knowledge Panel requires that Google can identify the entity unambiguously, describe it accurately, connect it to other recognized entities, and verify that representation from sources it trusts beyond your own website.
Common Sources Associated with Knowledge Panels
Google hasn’t published an authoritative list of exactly which sources it draws from when constructing Knowledge Panels. What follows reflects what is commonly understood and observed, not a confirmed specification.
Website content
Your own site, particularly a well-structured entity homepage with factual, consistent information about your organization or personal profile, is a primary starting point. It is not sufficient on its own, but it anchors everything else.
Structured data
Schema markup (Organization, Person, Article) makes your entity’s attributes and relationships explicitly machine-readable. It does not create a Knowledge Panel, but it removes the ambiguity that would otherwise slow or prevent entity recognition.
Official profiles
Google Business Profile entries, verified social media accounts, and professional directory listings contribute corroborating signals about your entity’s existence and attributes.
Trusted publications
Coverage in credible, established publications that Google already recognizes as authoritative sources carries significant weight. An article that names your entity, describes what it does, and places it in a professional context is a meaningful corroboration signal.
Wikidata
Wikidata is an open, structured knowledge base that feeds directly into Google’s understanding of entities. A well-maintained Wikidata entry is one of the highest-value external signals for Knowledge Panel development, with lower barriers than Wikipedia. The Knowledge Graph guide covers Wikidata’s role in detail.
Wikipedia
Where a legitimate Wikipedia page exists, it is heavily weighted. However, Wikipedia has strict notability requirements and editorial standards. Attempting to create a Wikipedia page before meeting those standards is likely to backfire.
Social profiles
Consistent, complete profiles on LinkedIn, Twitter/X, and other recognized platforms provide third-party corroboration of your entity’s existence. Schema sameAs references on your site should link explicitly to these profiles to connect them to your entity definition.
Knowledge Panel Optimization
You cannot directly create a Knowledge Panel. You can build the entity foundation that makes one more likely. This process follows directly from the Entity SEO and Knowledge Graph work covered in the earlier guides in this series.
Define your entity precisely: your exact name, your category, your key attributes, and your key people. Build a structured entity homepage that functions as the machine-readable source of record for your organization. Build author pages for individuals. This is the groundwork everything else depends on. Full guidance is in the Entity SEO guide.
Connect your entity explicitly to the other entities it is related to: founders to organizations, organizations to their products, individuals to their areas of expertise. Make these relationships explicit through schema markup (founder, memberOf, author, sameAs) and through consistent on-page content that describes those connections factually.
Implement Organization schema with name, URL, logo, foundingDate, founder, and sameAs. Implement Person schema on all author and about pages. Implement Article schema on all published content with an explicit author reference. Use the Schema Markup Generator to build these and the Structured Data Testing Tool to validate them.
Every source that mentions your entity should use the same name, the same description, the same professional category. Inconsistencies across your website, your schema, your social profiles, and third-party mentions create disambiguation problems that reduce knowledge graph confidence and delay panel development.
Third-party corroboration is the input you cannot manufacture on your own timeline. Pursue genuine PR coverage, contribute to credible publications, maintain a Wikidata entry for your organization, and ensure your entity is accurately represented in relevant industry directories. Each credible mention that names your entity and describes it consistently is a corroboration signal.
Knowledge Panels are more likely for entities that have a demonstrated track record of recognized work: original research, notable projects, verifiable expertise, and consistent engagement with credible sources over time. This is the authority layer that separates an entity with good schema from an entity that Google is confident enough to surface publicly.
Common Knowledge Panel Myths
Several persistent beliefs about Knowledge Panels lead to wasted effort and misaligned strategy. Each of these is false.
❌ Myth 1: Schema markup creates a Knowledge Panel
Schema markup is a structured data format that helps search engines read your entity’s attributes more clearly. It is an input to entity recognition, not a trigger for Knowledge Panel creation. Many sites with perfectly implemented schema have no Knowledge Panel. Many sites with weak schema have one. Schema is necessary groundwork, not a direct cause.
❌ Myth 2: A Wikipedia page guarantees a Knowledge Panel
A Wikipedia page is a strong corroboration signal, but it is not a guarantee of anything. Knowledge Panels can exist without Wikipedia, and Wikipedia pages can exist for entities that have no Knowledge Panel. Wikipedia is one input among many. Pursuing a Wikipedia page as a shortcut to a Knowledge Panel, particularly if your entity doesn’t meet Wikipedia’s notability standards, is more likely to result in a deleted page than a panel.
❌ Myth 3: Backlinks create a Knowledge Panel
Link building for traditional SEO rankings and entity building for Knowledge Panels are different disciplines with different signals. A high volume of backlinks from low-quality or irrelevant sources contributes nothing to entity recognition or knowledge graph inclusion. The signals that matter for Knowledge Panels are entity clarity, attribute consistency, and corroboration from credible, recognized sources, not link quantity.
❌ Myth 4: Knowledge Panels are only for celebrities and major brands
This is false, and it is one of the most limiting beliefs in Entity SEO. Knowledge Panels exist for executives of mid-sized companies, authors of niche books, researchers in specialized fields, local businesses with strong entity presence, and many other non-celebrity entities. The threshold is entity clarity and corroboration, not fame. A clearly defined, well-documented entity in a niche space can develop a panel more easily than a large brand with inconsistent entity representation.
❌ Myth 5: Once you have a Knowledge Panel, the work is done
Knowledge Panels can display inaccurate information, can be updated to reflect outdated attributes, and can disappear if entity signals weaken over time. Maintaining accurate entity information across all sources, keeping schema updated, and continuing to earn relevant mentions are ongoing requirements, not one-time tasks.
Knowledge Panel Eligibility: The Visiblytics Framework
This is the framework I use at Visiblytics to evaluate an entity’s readiness for Knowledge Panel development. It breaks eligibility into five dimensions, each of which can be assessed and improved independently.
Identity: Who are you?
Is your entity clearly defined with a consistent name, a specific category, and complete attributes? An entity that is ambiguously named, inconsistently described, or under-attributed is not a strong Knowledge Panel candidate regardless of how authoritative it otherwise is. Identity is the entry requirement. Without it, the other dimensions have nothing to build on.
Consistency: Is information aligned?
Does the same entity information appear consistently across your website, your schema markup, your social profiles, your Wikidata entry, and third-party mentions? Inconsistencies are disambiguation costs. Every version of your brand name that differs from your official name, every job title that contradicts another source, every description that conflicts with your schema, is a reduction in Google’s confidence that it knows exactly which entity it is looking at.
Authority: Are you referenced by credible sources?
Are there credible, independent sources that mention your entity, describe it accurately, and place it in its professional context? This is the corroboration layer. Your own website is not sufficient. The authoritative mentions, the Wikidata entries, the industry directory presences, the publication coverage: these are what allow Google to verify your entity from outside your own domain.
Relationships: Are connections clear?
Are your entity’s connections to other recognized entities explicit and machine-readable? Founder-to-company, author-to-publication, brand-to-product relationships that are declared in schema and corroborated externally carry significantly more weight than relationships that only appear in prose on your own site. Relationship clarity is what connects your entity to the broader knowledge graph network rather than leaving it as an isolated node.
Recognition: Can search engines validate you?
Has your entity crossed the threshold where independent, structured sources confirm its existence and attributes? This is the cumulative result of the four dimensions above. Recognition is not something you declare about yourself: it is the outcome of Identity, Consistency, Authority, and Relationships all being strong enough that Google can confirm your entity through its own verification process rather than relying solely on your self-reported information.
Knowledge Panel Eligibility Signals
The five dimensions above describe what to build. This section describes the sequence those signals follow on the path to eligibility. These are not ranking factors. They are not guarantees. They are signals, and they build on each other in order.
This is the prerequisite. Without a precisely defined, unambiguously named entity, every signal that follows is weakened. A brand that isn’t sure what it wants to be called, or that uses different descriptions in different places, is diluting its own entity signal before the process has even started.
This is what allows signals from multiple sources to reinforce each other rather than contradict each other. When your website, your schema, your social profiles, and your Wikidata entry all describe the same entity the same way, each source multiplies the confidence of the others. When they conflict, they cancel each other out.
Structured Data makes the entity explicitly machine-readable. It removes the inference step that a crawler would otherwise have to take when reading prose about your entity. Schema tells a search engine directly: this page is about this Organization, this person is its Founder, these are its sameAs references. No schema means relying entirely on the crawler’s ability to extract that information from unstructured text.
Authoritative Mentions are the external corroboration layer that no amount of on-site work can replace. A Wikidata entry, a mention in a credible publication, a listing in a recognized industry directory: these are signals from outside your own domain that your entity is real and recognized. This is the layer that most businesses underinvest in because it requires genuine credibility work rather than technical implementation.
Strong Entity Relationships are what connect your entity to the broader knowledge graph network rather than leaving it as an isolated node. A person connected to an organization, an organization connected to its products and topics, an author connected to their published work: these relationships are what allow a knowledge graph to answer multi-hop questions about your entity and what make your entity useful to the broader network, not just defined within it.
Each signal in this chain is necessary. None is sufficient alone. A brand with perfect schema and no external mentions has built half the foundation. A brand with strong press coverage and no structured data has built the other half. Knowledge Panel eligibility consistently comes from the full chain, not from any single layer.
Knowledge Panel Examples: What They Tell You
Each example below is worth reading analytically, not just visually. Every element visible in a Knowledge Panel maps to a specific entity component: an entity identifier, an attribute, a relationship, or a corroborating source. Reading panels this way shows you exactly what the underlying entity work produced.
Example 1: Steve Jobs (Person entity)
This is a person entity panel. Here is what each visible element represents:
- Entity: Steve Jobs is the core entity. His name is the identifier that anchors the panel. Google has resolved “Steve Jobs” to a single, unambiguous person entity, distinct from any other entity that might share similar terms.
- Attributes: The description (co-founder of Apple, Pixar, NeXT), birth date, death date, and nationality are all attributes of the person entity. These are facts associated with this specific node in the knowledge graph, drawn from structured sources including Wikidata and Wikipedia.
- Relationships: The links to Apple, NeXT, and Pixar visible in the panel are entity relationships. Each one is a directional edge in the knowledge graph: Steve Jobs co-founded Apple, Steve Jobs founded NeXT, Steve Jobs acquired and led Pixar. These are not mentioned casually: they are structured, typed relationships that have been corroborated across multiple independent sources.
- Sources: The corroboration behind this panel includes Wikipedia, Wikidata, Apple’s official corporate history, countless books and publications, and decades of consistent media coverage. No single source created this panel. The consistency and volume of corroboration across trusted sources is what produced it.
The lesson for your entity: The structure of this panel (identifier, attributes, relationships, related entities) is the same structure any person entity panel follows. The difference between Steve Jobs’ panel and an emerging professional’s panel is not format: it is the depth and breadth of external corroboration.
Example 2: Google (Organization entity)
This is an organization entity panel. Here is what each visible element represents:
- Entity: Google is the core entity. The panel identifies it specifically as a technology company, disambiguating it from other potential uses of the word “Google.” The entity type (organization) shapes what attributes and relationships are displayed.
- Attributes: The founding date, headquarters location, industry category, CEO, and revenue (where shown) are all attributes of the organization entity. These are the properties that define what Google is, drawn from structured sources including Wikidata, Google’s own structured data, and trusted business databases.
- Relationships: The founders (Larry Page and Sergey Brin) appear as linked person entities, each with their own knowledge graph node. Subsidiary products and companies (YouTube, Android, DeepMind) appear as related entity links. Each of these is a typed relationship: Larry Page co-founded Google, YouTube is owned by Google. These relationships are bidirectional in the knowledge graph: navigating from Google reaches Page, and navigating from Page reaches Google.
- Sources: Google’s own structured data, Wikidata, Wikipedia, SEC filings, trusted business publications, and consistent representation across thousands of credible sources. For an organization at this scale, corroboration is overwhelming. For a smaller brand, the same principle applies at a proportionally smaller scale.
The lesson for your entity: An organization entity panel requires the same core components regardless of company size: a clear name, a defined category, a founding date, named founders or key people (who are themselves entity-linked), and a consistent description. The panel for a small consultancy follows the same template as Google’s. The difference is how deeply those components are corroborated externally.
Example 3: Taylor Swift (Brand or public figure with rich entity network)
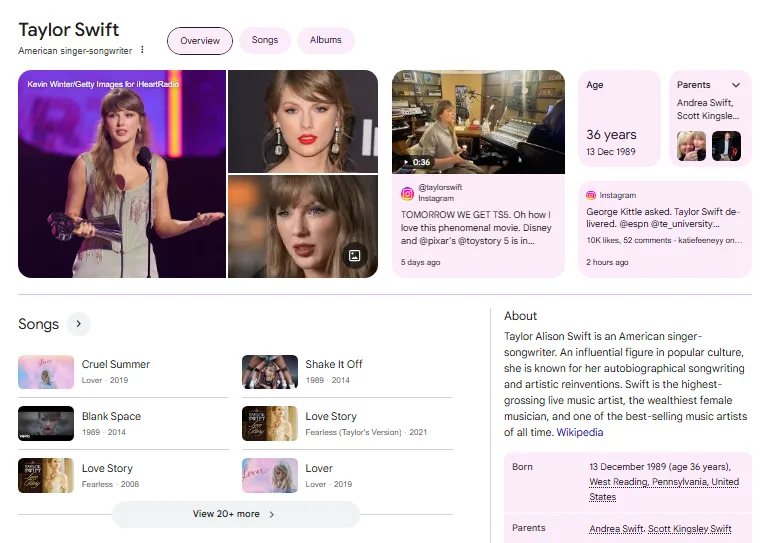
This is a person entity panel with an unusually dense relationship network. Here is what each visible element represents:
- Entity: Taylor Swift is the core entity, classified as a person and specifically as a musician and public figure. The entity type shapes which attributes and relationships Google surfaces in the panel.
- Attributes: Genre, birth date, nationality, active years, and associated record labels are attributes of this person entity. These are properties attached to her specific node in the knowledge graph.
- Relationships: Albums appear as product entities linked to her. Record labels appear as organization entities. Related artists appear as person entities. Each of these is a typed relationship in the knowledge graph: Taylor Swift recorded this album, Taylor Swift is signed to this label, Taylor Swift has collaborated with or is related to these artists. The richness of the panel reflects the richness of the relationship network built around her entity over time.
- Sources: Wikipedia, Wikidata, music databases like Discogs and AllMusic, major music publications, official artist profiles, and years of consistent structured coverage across the music industry.
The lesson for your entity: This panel illustrates how a knowledge graph panel deepens over time as more relationships are established and verified. An author who publishes one book has one product entity relationship. An author who publishes ten books, contributes to publications, is cited in other works, and is associated with a recognized area of expertise has a far richer relationship network, and a correspondingly richer panel. Every relationship you establish and verify today is a future panel element.
Knowledge Panels and AI Visibility
Knowledge Panels are not just a search feature. They are a signal that feeds directly into how AI systems understand and represent your entity.
When an AI system like ChatGPT, Gemini, Claude, or Perplexity constructs an answer that involves your brand, it is drawing on structured knowledge about entities in your space. An entity that has reached Knowledge Panel status has, by definition, crossed the threshold where one of the world’s most sophisticated entity-recognition systems has verified it as real, distinct, and well-understood. That verification feeds into AI training data, AI retrieval systems, and AI citation confidence.
This is why Knowledge Panel development is Pillar 3 in the AI Visibility framework, sitting directly between Knowledge Graph work and the LLM SEO layer. It is the point in the architecture where entity work becomes publicly visible and AI-verifiable.
Brands that have built strong entity foundations and knowledge graph presence, and have reached Knowledge Panel eligibility, are the brands that AI systems can cite with the most confidence. The panel is not the end of the work. But it is a meaningful marker that the foundational work is producing results.
Future Knowledge Panel Resources
The following concepts will each receive standalone treatment as the Visiblytics resource library grows:
Knowledge Panel Claiming
how to claim a Knowledge Panel once it appears, so you can suggest edits and corrections
coming soonKnowledge Panel Verification
the verification process for individuals and organizations
coming soonKnowledge Panel Optimization
a detailed guide to improving existing panel content and accuracy
coming soonBrand Knowledge Panels
specific considerations for company and product entity panels
coming soonPersonal Knowledge Panels
specific considerations for individual and author entity panels
coming soonKnowledge Panel Audits
how to evaluate an existing panel for accuracy and completeness
coming soonFrequently Asked Questions
A Knowledge Panel is an information box that appears in Google Search results for recognized entities, displaying structured information about that entity including its description, key attributes, and relationships to other entities. It is generated from Google’s knowledge graph data and appears without the user needing to visit any website. It is one of the clearest visible signals that Google has identified and verified an entity with sufficient confidence.
Knowledge Panels work as an output of Google’s knowledge graph. When Google has gathered enough corroborated, consistent information about an entity to reach a confidence threshold, it synthesizes that information into a structured panel. The panel draws from multiple sources including website content, structured data, Wikidata, and trusted publications. The exact confidence threshold is not published by Google.
A Knowledge Graph is the underlying data infrastructure that stores entities and their relationships. A Knowledge Panel is a visible search feature that displays a summary of what the Knowledge Graph knows about a specific entity. The Knowledge Graph is invisible and affects all of Google’s search and AI understanding. The Knowledge Panel is visible and affects how your entity appears for branded searches specifically. Full comparison is in the Knowledge Graph guide.
Yes. Knowledge Panels are not reserved for celebrities or large corporations. Small businesses, individual consultants, niche authors, and specialized brands can and do develop Knowledge Panels. The requirement is entity clarity, consistency, and external corroboration, not size or fame. A clearly defined small business with strong schema, a Wikidata entry, and consistent third-party mentions is a stronger Knowledge Panel candidate than a large brand with inconsistent entity representation.
No. Schema markup helps search engines read your entity’s attributes more clearly, which is a necessary input to the process. But schema alone does not trigger a Knowledge Panel. Many entities with complete, error-free schema have no panel. The panel requires corroborated entity presence across multiple independent sources, not just well-implemented structured data on your own site.
I cannot give a verified timeline, and I would be cautious of any source that states one with certainty. It depends heavily on your starting point, your industry, how quickly you can build third-party corroboration, and factors internal to Google that are not publicly documented. The technical groundwork (schema, entity pages) can be implemented in days. The external corroboration that drives panel eligibility builds over months. Some entities develop panels relatively quickly; others with strong entity foundations never develop one. The goal is strong entity work, not a panel on a deadline.
Yes, in several ways. A Knowledge Panel occupies significant space on the results page for branded searches, increasing visibility. It reinforces brand recognition with users who encounter your entity through non-branded searches. It signals entity verification to search systems that use that signal to inform broader search understanding. The precise impact on rankings is not something Google has quantified publicly, but the role of entity recognition in modern search is well established.
Yes. A Knowledge Panel is a visible confirmation that your entity has reached a level of structured representation that AI systems can draw on confidently. AI tools like ChatGPT, Gemini, Claude, and Perplexity draw on structured entity knowledge when constructing answers. An entity with Knowledge Panel-level corroboration is more likely to be cited accurately and more likely to be included in AI-generated answers about its area of expertise. Full detail on the connection is in the AI Visibility guide.
The Panel Is Not the Goal. The Entity Is.
A Knowledge Panel is a confirmation, not a destination.
It appears when your entity work has reached the point where Google is confident enough to display what it knows about you publicly. That confidence is built through the four pillars that lead to this one: clearly defined entities through Entity SEO, connected relationships through Knowledge Graph work, and the consistent, corroborated, authoritative presence that the Visiblytics eligibility framework measures.
Every brand that focuses on building a genuine, well-structured entity, earning real recognition, and maintaining consistency across every surface it appears on, is doing the work that Knowledge Panels are built from. The panel, if it comes, is evidence that the work is real. It is not the work itself.
The next pillar, LLM SEO, covers what happens when that entity foundation meets the specific retrieval and citation mechanics of large language models.